مسائل اساسی اجرای Vq در visual studio بر روی تصویر
1- چه نوع تصویری را برای کار انتخاب کنیم (JPG/BMP/...)؟
در اجرای پروژه های تحقیقاتی در صورتی که هدف فرمت خاصی نباشد و تحقیق در مورد مسائل دیگری باشد. فرمت های تصویری انتخاب می کنیم که کار ذخیره و بازیابی و انجام محاسبات روی آن آسان تر باشد.
2-تعداد بلاک های تصویر چند تایی باشد؟
3- تعداد خوشه ها چندتایی باشد؟
در VQ تعداد خوشه ها به تعداد بلاک هایی گفته می شود که از یک بلاک مرکز (Centroid) تبعیت می کنند. و نکته مهم این است که بلاک خوشه در همجواری مکانی با بلاک مرکز قرار ندارد بلکه از لحاظ محتوایی (رنگ پیکسل های درونی) شیبه بلاک مرکز می باشد. و تعداد آن بستگی به میزان شباهت بلاک ها با بلاک مرکز دارد.
4- خوشه بندی روی کدام داده ها اجرا می شود آیا بر اساس محل قرار گیری پیکسل ها و یا خصوصیات رنگی پیکسل ها می باشد؟
خوشه بندی بر روی پیکسل های تصوی انجام می شود و در خوشه بندی بر روی تصاویر منظور از فاصله اقلیدوسی فاصله رنگ ها نسبت به مرکز کلاسترمی باشد.مرکز کلاستر یک پیکسل از تصویر است که شباهت زیادی به پیسکل های تصویر درون خوشه خود دارد. اما در VQ خوشه بندی بر روی بلاک هایی تشکیل شده از پیکسل ها انجام می شود که به صورت n*n از درون تصویر استخراج می شوند. یعنی یک بلاک در مرکز یک خوشه از بلاک ها قرار می گیرد.
5-اندازه کدبوک چقدر باشد؟ و رابطه آن با تصویر اولیه و نهایی چیست؟
6- نحوه ذخیره سازی تصویر نهایی چگونه است؟
بررسی پارامتری VQ
روش شناسی

اندازه تصویر اصلی N×N (طول × عرض)
Nb تعداد کل بلاک های تصویر یا به عبارتی تعداد بلاکی که تصویر به آن تقسیم شده است.
تصویر را به بلوک های n×n تقسیم می کنیم.
n نشان دهنده (p×p) پیکسل
بنابراین تصویرهای کوچکی زیرمجوعه تصویراصلی و یا بلاک هایی به اندازه Nb=[N/n]×[N/n] داریم که آنهای را بردارهای ورودی با X={x1,x2,…, xNb} نمایش داده می شوند نام گذاری می کنیم، و در آن xi بردار ورودی با بعد های n×n می باشد.
مثال: xi= (xi1,xi2,…,xi(n×n))
کدبوکC = {c1,c2,…, cNc} که در آن NC تعداد کدوردها یا اندازه کدبوک میباشد. (Nb>>NC)
Ci شامل iامین کدورد (ci=(ci1,ci2,…, ci(n×n) به طول n×n می باشد.
در حقیقت به جای جستجو برای یک پیکسل به دنبال مجموعه از پیکسل ها هستیم که آن را وکتور می نامیم.
یک بردار کمی ساز Q با K بعد و انداز N این گونه تعریف می شود
یک نقشه برداری از بردار هایی در فضای اقلیدوسی K بعدی Rk حاوی N خروجی و یا بردار های تولید شده به نام کد ورد.
Q=RkK=>w
که در آن W=(wn;n=1,2,…N) مجموعه ای از بردارهای بازتولید (feature maps)) به نام کدبوک است.
Q(v) آدرس بردار های تولید شده از بردارهای ورودی (در مرحله رمز گزاری)
W آدرس بردار های تولید شده از بردارهای وارد شده از مرحله رمزگزاری (در مرحله رمزگشایی)
N کد ورد از فضای برداری مرتبط با N ناحیه از Rk مجموعه ورونویی (cluster voronoi partition) که به Rn;n=1,2,…,N معرفی می گردد و nامین ناحیه به وسیله رابطه زیر مشخص می شود:
Rn={v E Rk /Q(v)=wn}
training vectors : در VQ مبتنی بر تصویر، در ابتدا تصویر به بلوک های زیرمجموعه مجزا تجزیه می شود. هر زیر بلوک سپس به یک بردار یک بعدی تبدیل می شود که به عنوان بردار آموزشی تعریف می شود.
Codebook: با استفاده از یک مجموعه آموزش تصویری تولید می شود
منبع: https://pdfs.semanticscholar.org/6001/d0cc0d0a48a7f87874ffc1b1cbb75e675fba.pdf
چگونه می توان تعداد کلاستر بهینه را برای خوشه بندی K-,means پیدا کرد؟
اگر یک روش برای محاسبه تعداد مراکز کلاستر در k-means می خواهید ، می توانید از روش Elbow (منظور همان آرنج دست است که در نمودار مشخص شده است) استفاده کنید.در ابتدا، برای برخی مقادیر k (به عنوان مثال 2، 4، 6، 8 و غیره)، مجموع خطای مربع (SSE) محاسبه می شود. SSE به عنوان مجموع فاصله مربع بین هر عضو از خوشه و مرکز آن تعریف شده است. فرمول:
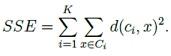
اگر شما k را نسبت به SSE بکشید، خواهید دید که خطای k کاهش می یابد؛ این به این دلیل است که وقتی تعداد خوشه ها افزایش می یابد، آنها باید کوچکتر باشند، بنابراین اعوجاج نیز کوچکتر است. ایده روش آرنج این است که k را انتخاب کنید که در آن SSE به طور ناگهانی کاهش می یابد. این همانطور که در تصویر زیر می بینید، "اثر آرنج" را در گراف تولید می کند:
در این مورد، k = 6 مقداری است که روش Elbow انتخاب کرده است. توجه داشته باشید که روش آرنج یک اکتشاف است
و به این ترتیب، ممکن است جواب دهد و یا ممکن است در مورد خاص شما جواب ندهد.
گاهی اوقات، بیش از یک آرنج وجود دارد، یا هیچ آرنجی وجود ندارد.
الگوریتم LBG
LBG (Linde–Buzo–Gray)
این الگوریتم توسط Linde،BuzoوGray در سال 1980 معرفی شد. و به منظور برطرف شدن چالشهای الگوریتم K-mean (تعیین تعداد خوشه ها در ابتدا )که از روشهای پایه خوشه بندی است ، از الگوریتم LBG استفاده میشود.
الگوریتم LBG یکی از الگوریتم های اکتشافی است . روند اجرایی LBG به این صورت است که در ابتدا یک خوشه در نظر گرفته می شود ، به عبارتی تمام دیتاها در قالب یک خوشه (K=1) قرار می گیرند.
سپس برای این خوشه یک بردار مرکز محاسبه میکند.(اجرای الگوریتم K-Means با تعداد خوشة (K=1) سپس این بردار را به 2 بردار میشکند و دادهها را با توجه به این دو بردار خوشهبندی میکند (اجرای الگوریتم K-Means با تعداد خوشة K=2 که مراکز اولیه خوشهها همان دو بردار هستند). در مرحلة بعد این دو نقطه به چهار نقطه شکسته میشوند و الگوریتم ادامه پیدا میکند تا تعداد خوشة مورد نظر تولید شوند .
عملکرد LBG را می توان به صورت دیگری نیز بیان کرد:
1- LBG در ابتدا با 2 کلاستر (خوشه) شروع می شود (اجرای K-Means با 2 کلاستر تا رسیدن به همگرایی).
2- تعیین واریانس خوشه ها .کلاستری که بیشترین واریانس را دارد به دو کلاستر تقسیم می شود(به طور کلی ،3 خوشه).
3- K-Means مجددا اجرا می شود تا به همگرایی برسد(در حال حاضر با 3 خوشه).
4- مرحله 2 و3 الگوریتم تکرار می شود تا زمانیکه تمام کلاسترها یافت شوند.

این الگوریتم به ما بهترین خوشه ها را می دهد بجای اینکه ، با K-Means در ابتدا کار با تعداد مشخصی از کلاستر (K) شروع کنیم. ما میتوانیم بجای اضافه کردن یک کلاستر در هربار (زمان) ، در هر جایی که کلاستر تفکیک شده ، تقسیم کننده باینری انجام دهیم. با تفکیک و جدا سازی یک کلاستر، فقط یک وکتور جزئی (بردار) به عنوان وکتورپارازیت اضافه شده و از کلاستر اصلی که بزرگتر است با کلاستری که اختلال-نویز اندکی دارد کارا آغاز میکنیم برای دور بعدی(مرحله ) K-Means.
Vector Quantization
کمی سازی برداری یا رقمی سازی برداری
همانطور که می دانیم تنوع رنگ در طبیعت بسیار زیاد است.اما هنگام تصویر گرفتن از طبیعت و مشاهده تصویر گرفته شده با دوربین یا موبایل و ... میبینیم که از برخی از رنگها صرف نظر شده است (کاهش تعداد پیکسلهای رنگی)،
همچنین باذخیره کردن تصویر به روی کامپیوتر،متوجه می شویم که تعداد پیکسلها کاهش یافته است، یا پیکسلهای مشابه ادغام می شوند و یا پیکسلهای مشابه به روی سیستم ثبت نمی شوند.
یکی از پرکاربردترین متدها به منظور فشرده سازی تصاویر، VQ می باشد.
پیکلسلهای تصویر را میتوان در قالب بلوکهای n*n در نظر گرفت. پیکسلها در هر بلوک به صورت سطر به سطر مرتب شده اند. VQ روشی است بر پایه متد خوشه بندی،یعنی گروه بندی کردن بردارهای (بلوک) مشابه در داخل یک کلاس. بردارها از دل داده هایی که از تصویراستخراج شده اند و به شکل بلوکهای n*n هستند بدست می آیند(مثلا 4*4).
روند فشرده سازی تصویر با VQ در سه فاز انجام می شود:
-تولید کدبوک -کدکردن (رمز گذاری) -دکد کردن (رمز گشایی)
در فاز اول یعنی تولید کدبوک ، از قبل مجموعه ای از کلمه هایی کد شده مبتنی بر بردارهای آموزشی تصویری تولید شده اند.
هدف اصلی ،پیداکردن مجموعه ای از نمایندگان از کلمه کدهاست تا از طریق نمایندگان بتوان تصویری با کمترین تحریف بعد از فشرده سازی ایجاد کرد.(انتخاب زیرمجموعه ای از کلمه کدها بعنوان نماینده)
با فشرده سازی تصویر ،رمز گذار( encoder ) ،آدرسی از کلمه کدها ایجاد میکند که به بردار تصویر ورودی نزدیک باشد. و رمز گشا(decoder) از این درسها برای بازیابی بردار تصویر استفاده میکند.
کتاب کد ،یک عامل کلیدی تاثیر گذار به روی کارایی فرایند فشرده سازی تصویر می باشد.
برای
تولید کدبوک الگوریتمهایی ارائه شده اند. مانند kmeans و LBG . الگوریتم LBG بر پایه تکرار است که مجموعه ای از کلمه کدهای نماینده را تولید
می کند تا میزان تحریف و اعوجاج را در طول بردارهای آموزشی کاهش دهد و به
حداقل رساند. این فرایند تولید کلمه کد،محاسبات فشرده ای دارد و برحسب
انتخاب اولیه کلمه کد، نرخ اعوجاج ،تحت تاثیرقرار میگیرد. و ممکن است در
انتها کدبوکی کمتر از حد مطلوب بدست آید.
تعداد وکتورهای آموزشی را با M و تعداد کلمه کدها رابا N نشان میدهیم.
مساله طراحی کدبوک می تواند به عنوان یک مساله خوشه بندی فرموله شود که M بر N تقسیم می شو د که خود یک مساله NP-hard است.برای M و N های بزرگ، یک الگوریتم جستجوی سنتی مانند LBG به سختی میتواند طبقه بندی بهینه کلی را بیابد.
Vector Quantization
This page contains information related to vector quantization (VQ). Currently this page includes information about VQ with regards to compression. In the future, we will make this page a more comprehensive VQ page.
In what applications is VQ used?
Vector quantization is used in many applications such as image and voice compression, voice recognition (in general statistical pattern recognition), and surprisingly enough in volume rendering (I have no idea how VQ is used in volume rendering!).
What is VQ?
A vector quantizer maps k-dimensional vectors in the vector space Rk into a finite set of vectors Y = {yi: i = 1, 2, ..., N}. Each vector yi is called a code vector or a codeword. and the set of all the codewords is called a codebook. Associated with each codeword, yi, is a nearest neighbor region called Voronoi region, and it is defined by:
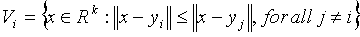
The set of Voronoi regions partition the entire space Rk such that:
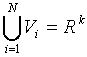
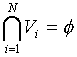 for all i
for all i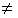 j
j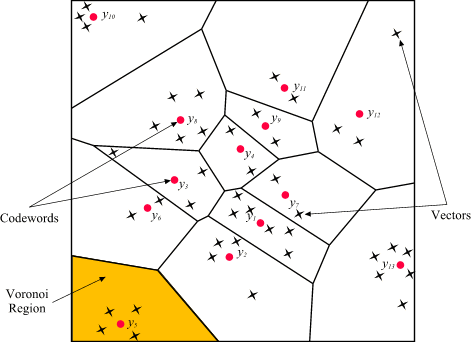 |
| Figure 1: Codewords in 2-dimensional space. Input vectors are marked with an x, codewords are marked with red circles, and the Voronoi regions are separated with boundary lines. |
The representative codeword is determined to be the closest in Euclidean distance from the input vector. The Euclidean distance is defined by:
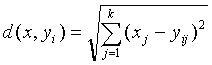
where xj is the jth component of the input vector, and yij is the jth is component of the codeword yi.
How does VQ work in compression?
 |
| Figure 2: The Encoder and decoder in a vector quantizer. Given an input vector, the closest codeword is found and the index of the codeword is sent through the channel. The decoder receives the index of the codeword, and outputs the codeword. |
How is the codebook designed?
So far we have talked about the way VQ works, but we haven't talked about how to generate the codebook. What code words best represent a given set of input vectors? How many should be chosen?
The algorithm
- Determine the number of codewords, N, or the size of the codebook.
- Select N codewords at random, and let that be the initial codebook. The initial codewords can be randomly chosen from the set of input vectors.
- Using the Euclidean distance measure clusterize the vectors around each codeword. This is done by taking each input vector and finding the Euclidean distance between it and each codeword. The input vector belongs to the cluster of the codeword that yields the minimum distance.
- Compute the new set of codewords. This is done by obtaining the average of each cluster. Add the component of each vector and divide by the number of vectors in the cluster.
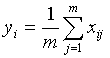
- Repeat steps 2 and 3 until the either the codewords don't change or the change in the codewords is small.
There are many other methods to designing the codebook, methods such as Pairwise Nearest Neighbor (PNN), Simulated Annealing, Maximum Descent (MD), and Frequency-Sensitive Competitive Learning (FSCL), etc.
How does the search engine work?
Although VQ offers more compression for the same distortion rate as scalar quantization and PCM, yet is not as widely implemented. This due to two things. The first is the time it takes to generate the codebook, and second is the speed of the search. Many algorithms have be proposed to increase the speed of the search. Some of them reduce the math used to determine the codeword that offers the minimum distortion, other algorithms preprocess the codewords and exploit underlying structure.
The simplest search method, which is also the slowest, is full search. In full search an input vector is compared with every codeword in the codebook. If there were M input vectors, N codewords, and each vector is in k dimensions, then the number of multiplies becomes kMN, the number of additions and subtractions become MN((k - 1) + k) = MN(2k-1), and the number of comparisons becomes MN(k - 1). This makes full search an expensive method.
What is the measure of performance VQ?
How does one rate the performance of a compressed image or sound using VQ? There is no good way to measure the performance of VQ. This is because the distortion that VQ incurs will be evaluated by us humans and that is a subjective measure. Don't despair! We can always resort to good old Mean Squared Error (MSE) and Peak Signal to Noise Ratio (PSNR). MSE is defined as follows:
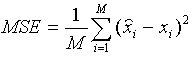
where M is the number of elements in the signal, or image. For example, if we wanted to find the MSE between the reconstructed and the original image, then we would take the difference between the two images pixel by pixel, square the results, and average the results.
The PSNR is defined as follows:
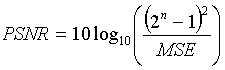
where n is the number of bits per symbol. As an example, if we want to find the PSNR between two 256 gray level images, then we set n to 8 bits.