الگوریتم Kmeans
الگوریتم های کلاسترینگ
خوشه بندی و یا آنالیز خوشه ای ، گروهی از اشیا داده ای که تنها براساس اطلاعات به دست آمده از داده ها کار می کند که به توصیف اشیاارتباط بین آنها می پردازد.هدف این است که اشیا درون یک گروه شبیه باشند و اشیا درون گروه های مختلف متفاوت باشند.
کیفیت خوشه ها بر اساس تمایز بین گروه ها و همسان بودن درونی گروه ها تعیین می شود. در دامنه ای از تصاویر این توصیف کلی به فاصله پیکسل ها در فضای رنگی تفسیر می شود پیکسل هایی که در کنار یکدیگر در یک کلاستر می باشند.
Kmeans
یک الگوریتم تکرار شونده است که تعداد کلاستر ها را قبل از اجرا تعیین می کند. در ابتدا مرکز حجم K به وسیله قوانینی تعیین می شود.(در ابتدا به صورت تصادفی با استفاده از نقاط داده ) و آنها وزن مرکز کلاستر را تعیین می کنند
برای هر نقطه داده یک مرکز حجم محاسبه می شود. در نتیجه کلاستری هایی از نقاط تشکیل می شود و در مرحله بعد تمام نقاط به کلاستر ها می پیوندند این روند ادامه پیدا می کند تا شرط پایان برسد.
در این روش ، در ابتدا تعداد خوشه ها مشخص می شود (K) و برای هرخوشه ، یک
نمونه داده از بین داده های موجود ، بعنوان هسته خوشه (مرکز خوشه) در نظر
گرفته می شود.
با توجه به اینکه در این روش ،از ابتدا تعداد خوشه ها مشخص شده است و خوشهبندی K-Means به انتخاب اولیه خوشهها بستگی دارد، نتایج خوشه بندی در حین تکرار الگوریتم ، متفاوت می شود.
Algorithm 1 Basic K-means algorithm
1- انتخاب K نقطه به عنوان مرکز حجم های اولیه به صورت تصادفی
تکرار
2- اضافه کردن نقاط به نزدیک ترین مرکز حجم از کلاستر های K
3- محاسبه مجدد حجم هر کلاستر
پایان زمانی که شرط پایان برسد و دیگر تغییری در مراکز حجم ها به وجود نیاید
برای محاسبه فاصله مرکز حجم c تا نقطه x از رابطه زیر استفاده می کنیم
ِ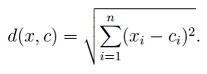
-شرایط پایان الگوریتم
دستیابی به حداکثر تعداد تکرار ها
مرکز حجم ها کمینه شود(Local or Global)- تغییر زیادی در محل حجم ها به وجود نیاید.

c' مرکز حجم به روز شده c و d مقدار جابه جایی که کمتر یا مساوی ازr حداکثر جابه جایی است
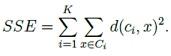
در کلاستر بندی تصاویر شرط خاتمه دوم استفاده می شود
پیچیدگی K means از نوع NP-Hard می باشد