بررسی پارامتری VQ
روش شناسی

اندازه تصویر اصلی N×N (طول × عرض)
Nb تعداد کل بلاک های تصویر یا به عبارتی تعداد بلاکی که تصویر به آن تقسیم شده است.
تصویر را به بلوک های n×n تقسیم می کنیم.
n نشان دهنده (p×p) پیکسل
بنابراین تصویرهای کوچکی زیرمجوعه تصویراصلی و یا بلاک هایی به اندازه Nb=[N/n]×[N/n] داریم که آنهای را بردارهای ورودی با X={x1,x2,…, xNb} نمایش داده می شوند نام گذاری می کنیم، و در آن xi بردار ورودی با بعد های n×n می باشد.
مثال: xi= (xi1,xi2,…,xi(n×n))
کدبوکC = {c1,c2,…, cNc} که در آن NC تعداد کدوردها یا اندازه کدبوک میباشد. (Nb>>NC)
Ci شامل iامین کدورد (ci=(ci1,ci2,…, ci(n×n) به طول n×n می باشد.
در حقیقت به جای جستجو برای یک پیکسل به دنبال مجموعه از پیکسل ها هستیم که آن را وکتور می نامیم.
یک بردار کمی ساز Q با K بعد و انداز N این گونه تعریف می شود
یک نقشه برداری از بردار هایی در فضای اقلیدوسی K بعدی Rk حاوی N خروجی و یا بردار های تولید شده به نام کد ورد.
Q=RkK=>w
که در آن W=(wn;n=1,2,…N) مجموعه ای از بردارهای بازتولید (feature maps)) به نام کدبوک است.
Q(v) آدرس بردار های تولید شده از بردارهای ورودی (در مرحله رمز گزاری)
W آدرس بردار های تولید شده از بردارهای وارد شده از مرحله رمزگزاری (در مرحله رمزگشایی)
N کد ورد از فضای برداری مرتبط با N ناحیه از Rk مجموعه ورونویی (cluster voronoi partition) که به Rn;n=1,2,…,N معرفی می گردد و nامین ناحیه به وسیله رابطه زیر مشخص می شود:
Rn={v E Rk /Q(v)=wn}
training vectors : در VQ مبتنی بر تصویر، در ابتدا تصویر به بلوک های زیرمجموعه مجزا تجزیه می شود. هر زیر بلوک سپس به یک بردار یک بعدی تبدیل می شود که به عنوان بردار آموزشی تعریف می شود.
Codebook: با استفاده از یک مجموعه آموزش تصویری تولید می شود
منبع: https://pdfs.semanticscholar.org/6001/d0cc0d0a48a7f87874ffc1b1cbb75e675fba.pdf
چگونه می توان تعداد کلاستر بهینه را برای خوشه بندی K-,means پیدا کرد؟
اگر یک روش برای محاسبه تعداد مراکز کلاستر در k-means می خواهید ، می توانید از روش Elbow (منظور همان آرنج دست است که در نمودار مشخص شده است) استفاده کنید.در ابتدا، برای برخی مقادیر k (به عنوان مثال 2، 4، 6، 8 و غیره)، مجموع خطای مربع (SSE) محاسبه می شود. SSE به عنوان مجموع فاصله مربع بین هر عضو از خوشه و مرکز آن تعریف شده است. فرمول:
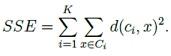
اگر شما k را نسبت به SSE بکشید، خواهید دید که خطای k کاهش می یابد؛ این به این دلیل است که وقتی تعداد خوشه ها افزایش می یابد، آنها باید کوچکتر باشند، بنابراین اعوجاج نیز کوچکتر است. ایده روش آرنج این است که k را انتخاب کنید که در آن SSE به طور ناگهانی کاهش می یابد. این همانطور که در تصویر زیر می بینید، "اثر آرنج" را در گراف تولید می کند:
در این مورد، k = 6 مقداری است که روش Elbow انتخاب کرده است. توجه داشته باشید که روش آرنج یک اکتشاف است
و به این ترتیب، ممکن است جواب دهد و یا ممکن است در مورد خاص شما جواب ندهد.
گاهی اوقات، بیش از یک آرنج وجود دارد، یا هیچ آرنجی وجود ندارد.
الگوریتم LBG
LBG (Linde–Buzo–Gray)
این الگوریتم توسط Linde،BuzoوGray در سال 1980 معرفی شد. و به منظور برطرف شدن چالشهای الگوریتم K-mean (تعیین تعداد خوشه ها در ابتدا )که از روشهای پایه خوشه بندی است ، از الگوریتم LBG استفاده میشود.
الگوریتم LBG یکی از الگوریتم های اکتشافی است . روند اجرایی LBG به این صورت است که در ابتدا یک خوشه در نظر گرفته می شود ، به عبارتی تمام دیتاها در قالب یک خوشه (K=1) قرار می گیرند.
سپس برای این خوشه یک بردار مرکز محاسبه میکند.(اجرای الگوریتم K-Means با تعداد خوشة (K=1) سپس این بردار را به 2 بردار میشکند و دادهها را با توجه به این دو بردار خوشهبندی میکند (اجرای الگوریتم K-Means با تعداد خوشة K=2 که مراکز اولیه خوشهها همان دو بردار هستند). در مرحلة بعد این دو نقطه به چهار نقطه شکسته میشوند و الگوریتم ادامه پیدا میکند تا تعداد خوشة مورد نظر تولید شوند .
عملکرد LBG را می توان به صورت دیگری نیز بیان کرد:
1- LBG در ابتدا با 2 کلاستر (خوشه) شروع می شود (اجرای K-Means با 2 کلاستر تا رسیدن به همگرایی).
2- تعیین واریانس خوشه ها .کلاستری که بیشترین واریانس را دارد به دو کلاستر تقسیم می شود(به طور کلی ،3 خوشه).
3- K-Means مجددا اجرا می شود تا به همگرایی برسد(در حال حاضر با 3 خوشه).
4- مرحله 2 و3 الگوریتم تکرار می شود تا زمانیکه تمام کلاسترها یافت شوند.

این الگوریتم به ما بهترین خوشه ها را می دهد بجای اینکه ، با K-Means در ابتدا کار با تعداد مشخصی از کلاستر (K) شروع کنیم. ما میتوانیم بجای اضافه کردن یک کلاستر در هربار (زمان) ، در هر جایی که کلاستر تفکیک شده ، تقسیم کننده باینری انجام دهیم. با تفکیک و جدا سازی یک کلاستر، فقط یک وکتور جزئی (بردار) به عنوان وکتورپارازیت اضافه شده و از کلاستر اصلی که بزرگتر است با کلاستری که اختلال-نویز اندکی دارد کارا آغاز میکنیم برای دور بعدی(مرحله ) K-Means.